入门课程:
https://openclaw101.dev/zh
https://claw101.com/
https://github.com/pudge0313/openclaw-
https://www.openclaw101.club/
参考文章:
一文彻底搞懂 OpenClaw 的架构设计与运行原理(万字图文) - AI架构师汤师爷 - 博客园
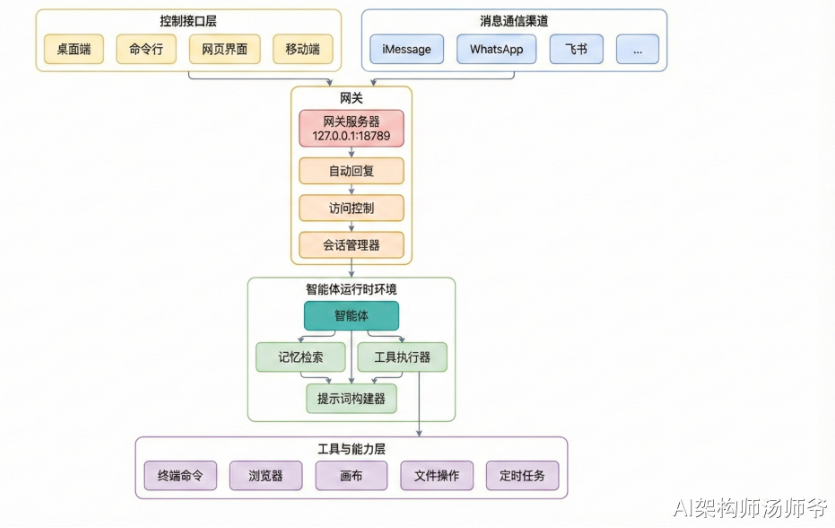
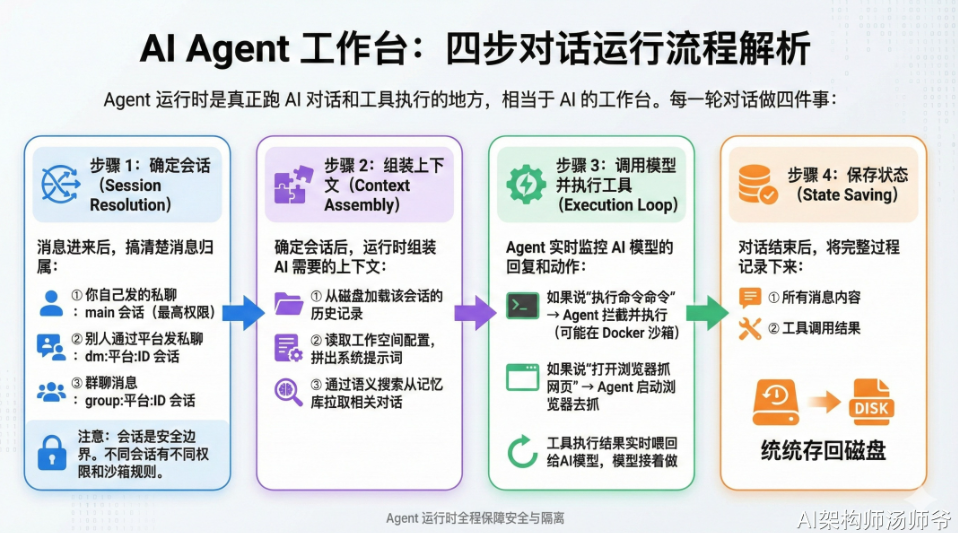
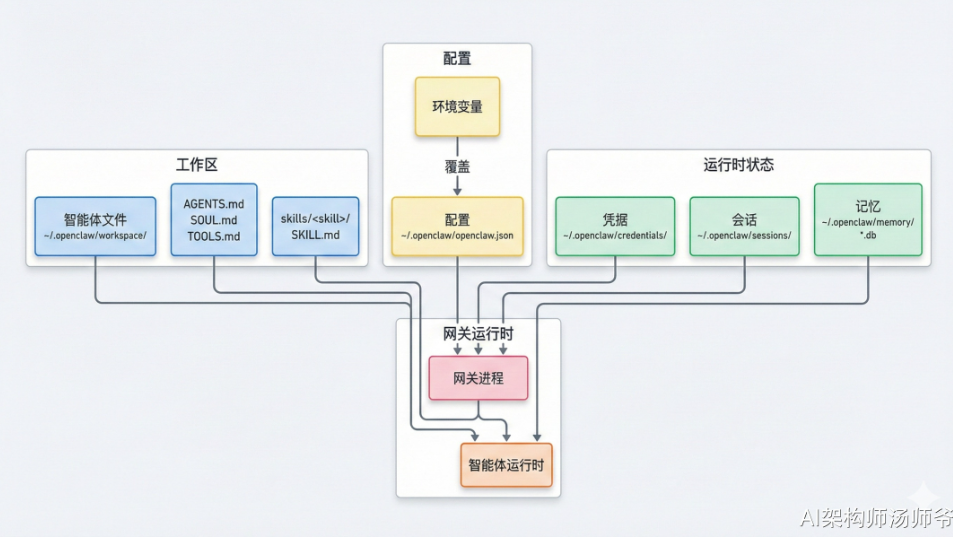
1. OpenClaw 软件架构概览
OpenClaw 的架构核心在于**“感知-推理-执行”**的异步循环。它不像传统的线性 API 调用,而是一个基于状态机的自治系统。
1.1 核心组件分层
- 接入层 (Adapter Layer): 适配不同的大模型后端(Claude 3.5/4, GPT-4, Llama 3)。
- 内核层 (Kernel/Orchestrator): 负责 Prompt 模板组装、Context 窗口管理以及 Token 消耗优化。
- 工具箱 (Tool Registry): 插件化管理,支持文件读写、搜索、代码执行等能力。
- 存储层 (State Memory): 维护对话树(Conversation Tree)和短期/长期记忆。
2. 工作目录结构详解
一个标准的 OpenClaw 项目目录是高度模块化的,遵循“配置与代码分离”的原则:
Plaintext
/openclaw
├── config/ # 全局配置文件 (API Keys, 模型参数, 角色设定)
├── src/
│ ├── agents/ # 核心智能体逻辑
│ ├── tools/ # 自定义工具集 (如 shell_executor.py, web_searcher.py)
│ ├── memory/ # 向量数据库及缓存管理
│ └── utils/ # 日志、加密及 Token 计算器
├── prompts/ # 系统提示词模板 (System Prompts)
├── workspace/ # 智能体执行任务时的临时工作区 (沙箱)
├── logs/ # 详细的执行链路追踪 (Trace Logs)
└── main.py # 程序入口
3. 交互对话流程 (Interaction Flow)
OpenClaw 的对话不是简单的 Q -> A,而是一个递归反馈过程。
步骤解析:
- 输入预处理: 接收用户 Prompt,提取意图。
- 上下文检索: 从
memory/中检索相关历史片段,通过 $K$-最近邻算法(KNN)匹配语义。 - 系统注入: 将
prompts/system_base.txt与当前上下文合并。 - 模型推理: 发起流式请求。
- 输出解析: 实时监控返回内容。如果发现
<tool_code>标签,立即截断流并转入工具执行。
4. 任务多轮执行流程 (Loop Execution)
这是 OpenClaw 最强大的部分,通常被称为 ReAct (Reasoning and Acting) 模式。
执行深度拆解:
| 阶段 | 动作 | 说明 |
| THOUGHT | 逻辑拆解 | 模型在内部思考:为了完成任务,我需要分哪几步? |
| ACTION | 工具调用 | 模型决定调用特定工具,例如 list_files。 |
| OBSERVATION | 结果回传 | 系统执行工具并将结果(如文件列表)反馈给模型。 |
| RESPONSE | 最终汇总 | 当模型判断信息足够,则输出最终答案给用户。 |
多轮执行中的状态恢复:
如果任务中断,OpenClaw 会通过 workspace/ 下的 .checkpoint 文件恢复状态。它利用以下公式计算当前任务的置信度:
$$Confidence = \frac{\sum_{i=1}^{n} Success\_Signals}{Total\_Steps}$$
当置信度低于阈值时,系统会主动触发“自我修正”逻辑。
5. 核心技术特性:思维链 (CoT) 与 约束
- 隐形思考: OpenClaw 鼓励模型在返回结果前进行
<thinking>标注,这部分内容在 UI 层面可以选择性对用户隐藏,以保证界面的简洁。 - 严格约束: 通过正则表达式和 JSON Schema 强制要求模型输出符合规范的工具调用格式,避免因大模型“幻觉”导致的语法错误。
你这个问题本身就说明你是从企业架构和可控性角度在看 OpenClaw,而不是简单当个“对话壳子”在用。下面我给你一份体系化、工程级别的结构讲解。
(不会水字数,但我会覆盖:架构层、目录层、通信层、Agent层、多轮执行机制、MCP、Tool体系、生产部署关键点)
一、OpenClaw 总体架构模型
一句话定义
OpenClaw = LLM Runtime + Agent Orchestrator + Tool Router + Memory System + MCP Gateway
它不是“模型”,而是:
面向企业可控 Agent 的运行时框架
二、核心分层架构
┌────────────────────────┐
│ Frontend │
│ WebUI / API Client │
└────────────┬───────────┘
│
▼
┌────────────────────────┐
│ API Gateway │
│ REST / SSE / WS │
└────────────┬───────────┘
│
▼
┌────────────────────────┐
│ Conversation Engine │
│ (State + Memory) │
└────────────┬───────────┘
│
▼
┌────────────────────────┐
│ Agent Orchestrator │
│ Planner / Tool Router │
└────────────┬───────────┘
│
┌──────────────────┼──────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ LLM Provider │ │ Tool Runtime │ │ MCP Client │
│ OpenAI/Qwen │ │ local/remote │ │ External Sys │
└──────────────┘ └──────────────┘ └──────────────┘
三、核心模块拆解
1️⃣ API Gateway 层
职责:
- 提供 REST
- 提供 SSE 流式接口
- 处理认证
- 请求限流
- 租户隔离
典型接口:
POST /v1/chat/completions
POST /v1/agent/run
GET /v1/conversation/:id
SSE 流程
你之前问过 nginx 代理 SSE ——OpenClaw 内部是标准 chunked 流式输出。
client -> gateway
gateway -> agent
agent -> llm
llm stream back
gateway passthrough to client
2️⃣ Conversation Engine
这是很多人忽略的核心。
数据结构
conversation_id
├── messages[]
├── tool_calls[]
├── memory_snapshot
├── state_machine_state
内部状态机
INIT
↓
THINKING
↓
TOOL_CALL (optional)
↓
WAIT_TOOL_RESULT
↓
REASONING
↓
FINAL_RESPONSE
你可以把它理解为:
带状态机的对话控制器
四、Agent Orchestrator(最核心)
这是 OpenClaw 和普通 Chat API 最大区别。
功能
- 解析 LLM 的 tool_call
- 决定是否执行
- 执行顺序控制
- 多轮工具循环
- 终止判定
1️⃣ Tool Call 格式
LLM 输出:
{
"tool_call": {
"name": "query_inventory",
"arguments": {
"item_code": "A123"
}
}
}
Orchestrator:
if tool_call:
validate
permission_check
execute
append result to conversation
loop back to LLM
2️⃣ 多轮执行流程
User: 物料A库存不足怎么办?
LLM:
Step1: 调用 query_inventory
Tool:
返回库存=3
LLM:
Step2: 调用 create_purchase_order
Tool:
创建成功
LLM:
输出最终说明
内部执行循环:
for i in range(max_steps):
response = LLM(context)
if response contains tool_call:
execute tool
append tool result
else:
break
终止条件
- 无 tool_call
- 达到最大 step
- 出现 error
- 用户中断
五、Tool Runtime 架构
Tool 注册模型
tool_registry
├── tool_name
├── description
├── input_schema
├── permission
├── service_endpoint
你之前问 ERP Agent 化 ——这个 registry 是必须的。
否则:
Agent 可能乱调用接口。
六、MCP 机制
MCP = Model Context Protocol
它解决的问题:
LLM 怎么知道有哪些工具?怎么知道 schema?
MCP 工作流程
Agent -> MCP Server
获取:
- tool list
- input_schema
- metadata
LLM Prompt 内会插入:
Available Tools:
1. query_inventory(input_schema)
2. create_po(input_schema)
这一步是动态的。
七、Memory 系统
OpenClaw 的 memory 分三层:
1️⃣ 短期上下文
当前对话 messages[]
2️⃣ 长期存储
数据库:
- PostgreSQL(会话)
- 向量库(知识)
3️⃣ Agent 状态缓存
Redis:
- 任务执行状态
- 分布式锁
八、工作目录结构(Docker 部署典型)
以:
~/openclaw2/data
为例:
data/
├── config.yaml
├── models/
├── logs/
├── conversations/
├── plugins/
├── tool_cache/
├── vector_store/
└── runtime/
说明
| 目录 | 作用 |
|---|---|
| config.yaml | LLM provider、MCP配置 |
| conversations | 会话持久化 |
| plugins | 本地 tool 插件 |
| vector_store | 向量索引 |
| runtime | 执行状态 |
九、数据库模型简化示意
conversation 表
id
tenant_id
user_id
created_at
message 表
id
conversation_id
role
content
tool_call_json
tool_execution 表
id
conversation_id
tool_name
input
output
status
十、多租户隔离机制
如果用于 ERP SaaS 场景(你之前问过)
必须:
tenant_id
user_id
permission_scope
Tool 调用必须带:
X-Tenant-ID
X-User-ID
否则会出现:
Agent 越权查询别的公司库存
十一、并发与分布式执行
生产环境建议:
API Gateway × N
Agent Worker × M
Redis (锁)
Postgres
Vector DB
任务执行模型:
请求 -> 入队列 -> Worker 抢占 -> 执行
避免长任务阻塞。
十二、对话执行全过程(完整版时序)
Client
↓
Gateway
↓
Conversation Engine
↓
Agent Orchestrator
↓
LLM
↓
返回 tool_call
↓
Tool Runtime
↓
写入结果
↓
回到 LLM
↓
生成 final
↓
SSE 输出
十三、为什么它比 FastGPT 更“Agent”
FastGPT 更偏:
RAG + Prompt 管理
OpenClaw 更偏:
多轮决策 + Tool Loop 控制
你之前讨论 ERP 场景,其实 OpenClaw 更适合做:
- 自动下单
- 自动补货
- 自动审批流触发
- 跨微服务协调
十四、生产级必须注意的 8 个坑
- tool_call 无限循环
- LLM 幻觉调用不存在 tool
- MCP schema 不一致
- 租户隔离失败
- 长任务超时
- 并发锁冲突
- 日志无法审计
- 权限模型缺失
十五、企业级推荐架构(适合你做ERP集成)
Nginx
↓
OpenClaw Gateway
↓
Agent Worker
↓
Tool Registry Service
↓
ERP 微服务群
ERP API 必须 Agent 化:
不是:
POST /createOrder
而是:
tool: create_sales_order
input_schema:
customer
items
delivery_date
十六、总结一句话
OpenClaw 的本质是:
一个可控、可审计、可多轮执行的企业级 Agent Runtime
它的核心不是对话,而是:
- 状态机
- Tool 调度
- 多轮循环
- 权限控制
你这个问题本质是:
如何在 OpenAI SSE 协议模式 下,与 OpenClaw 对接,同时实现:
- 多轮对话记忆保留
- 单次任务的分批(分阶段)执行
- 任务过程可流式返回
我们从协议层 → 状态层 → 执行层 → 工程实现 四层拆开讲。
一、协议层:SSE 本身不负责“多轮”
关键事实
OpenAI 的 SSE 协议只是:
单 HTTP 请求内的流式返回
它 不负责对话状态保存。
也就是说:
POST /v1/chat/completions
stream: true
这一请求结束后:
- 连接关闭
- 模型状态清空
- 服务端不记忆
所以:
多轮对话一定是你(或 OpenClaw)保存 conversation_id 来实现
二、在 OpenClaw 中实现多轮对话
标准结构
{
"conversation_id": "abc123",
"messages": [
{ "role": "user", "content": "查询库存" }
],
"stream": true
}
OpenClaw 做三件事:
- 根据 conversation_id 取历史消息
- 拼接到 prompt
- 执行 Agent 循环
内部模型
Conversation
├── messages[]
├── tool_calls[]
├── state
三、单次任务分批执行(核心)
你要的是:
一个用户任务,分阶段执行,中间不断流式反馈
典型场景:
用户:帮我检查物料A库存,如果不足就自动生成采购单
执行步骤:
- LLM 决策
- 调用 query_inventory
- 返回库存
- 再决策
- 调用 create_po
- 最终总结
OpenClaw 的循环模型
while not finished:
llm_response = call_llm(context)
if tool_call:
execute_tool()
append_result()
else:
break
四、如何在 SSE 下“分批执行”
SSE 可以:
在每一步都向前端发送 partial event
设计模式:阶段流式输出
建议输出结构:
event: stage
data: {"phase":"thinking"}
event: stage
data: {"phase":"tool_call","tool":"query_inventory"}
event: stage
data: {"phase":"tool_result","result":{...}}
event: delta
data: {"content":"库存不足,已创建采购单"}
event: done
这样前端可以:
- 实时展示执行步骤
- 展示“正在查询库存…”
- 展示“正在创建采购单…”
五、关键点:任务分批执行 ≠ 多轮对话
这两个概念不同。
1️⃣ 多轮对话
跨 HTTP 请求:
用户1问
用户2问
用户3问
依赖 conversation_id
2️⃣ 单次任务分批执行
单 HTTP 请求内:
一个复杂任务
内部多次工具循环
依赖 Agent Loop
六、如何保证“单次任务可暂停/续跑”
如果任务特别复杂(ERP场景常见):
你需要:
引入 Task ID
{
"conversation_id": "abc",
"task_id": "task_001",
"stream": true
}
数据库保存:
task_id
├── current_step
├── executed_tools
├── state_snapshot
状态机模型
INIT
↓
CHECK_INVENTORY
↓
CREATE_PO
↓
FINISH
如果中断:
resume_task(task_id)
继续执行。
七、推荐的工程实现结构(适合你ERP架构)
结合你之前的 Spring Cloud 微服务场景:
Nginx
↓
OpenClaw Gateway (SSE)
↓
Agent Worker
↓
Task Queue (Redis / MQ)
↓
ERP 微服务
流式处理策略
- Worker 执行每一步
- 每一步写入 Redis
- Gateway 监听 Redis PubSub
- 推送到 SSE
八、避免的 5 个坑
1️⃣ SSE 连接超时
默认 nginx 会断 60s
必须:
proxy_read_timeout 3600;
2️⃣ tool_call 无限循环
必须限制:
max_steps = 8
3️⃣ 前端误以为“每个 delta 是最终结果”
必须区分:
- event: delta
- event: stage
- event: done
4️⃣ 任务阻塞
不要在 API 线程里执行工具
要用 Worker
5️⃣ 多租户污染
conversation 必须绑定:
tenant_id
user_id
九、完整执行时序图
Client
↓
POST stream=true
↓
Gateway
↓
Create Task
↓
Worker 执行 step1
↓
推送 SSE
↓
Worker 执行 step2
↓
推送 SSE
↓
LLM 输出 final
↓
done
十、如果你要做“工业级任务拆分”
建议使用:
两层循环模型
对话层(Conversation)
└── 任务层(Task)
└── 步骤层(Step)
这样可以:
- 保留多轮
- 一个对话里多个任务
- 每个任务可恢复
十一、总结一句话
SSE 只是传输通道。
真正实现:
多轮对话 + 单次任务分批执行
靠的是:
- Conversation 持久化
- Agent Loop
- Task 状态机
- 工具执行可回写
- 阶段式流式推送
下面给你一份工程级视角的说明,聚焦:
- OpenClaw 内部对话管理模型
- conversation_id 的生成、存储、生命周期
- 与 Agent 多轮执行、任务分批执行的关系
- 多租户与分布式场景下的 ID 设计
我会用偏架构/实现语言来讲,而不是产品说明书风格。
一、OpenClaw 对话管理的核心抽象
OpenClaw 内部至少有三个层级对象:
Tenant
└── Conversation
├── Message[]
├── ToolExecution[]
├── Task[]
└── State
⚠ 关键理解:
conversation ≠ 单次请求
conversation 是一个“可持久化的上下文容器”
二、Conversation 的内部数据模型
一个标准 conversation 结构应类似:
{
"id": "conv_9f8c3e...",
"tenant_id": "t001",
"user_id": "u123",
"title": "物料补货讨论",
"status": "active",
"memory_snapshot": "...",
"created_at": "...",
"updated_at": "..."
}
配套的 message 表:
{
"id": "msg_001",
"conversation_id": "conv_9f8c3e",
"role": "user | assistant | tool",
"content": "...",
"tool_call_json": {},
"step_index": 3,
"created_at": "..."
}
配套 tool 执行记录:
{
"id": "tool_exec_01",
"conversation_id": "conv_9f8c3e",
"task_id": "task_001",
"tool_name": "query_inventory",
"input": {...},
"output": {...},
"status": "success"
}
三、conversation_id 的本质
它是“上下文指针”
它的作用:
- 唯一标识一段历史上下文
- 绑定租户
- 绑定用户
- 提供状态恢复能力
它不是 session token。
四、conversation_id 的生成机制
通常实现方式:
1️⃣ UUID v4
conv_550e8400-e29b-41d4-a716-446655440000
优点:
- 分布式安全
- 无冲突
2️⃣ Snowflake ID(推荐企业环境)
适用于高并发 SaaS:
conv_187364827364827364
优势:
- 有时间顺序
- 便于数据库排序
- 更利于分表分库
3️⃣ 组合型 ID(多租户推荐)
conv_{tenantId}_{timestamp}_{random}
例如:
conv_t001_20260305101523_ab12
优点:
- 天然租户隔离
- 审计友好
五、对话生命周期(内部状态机)
CREATED
↓
ACTIVE
↓
IDLE
↓
ARCHIVED
↓
DELETED
解释:
| 状态 | 说明 |
|---|---|
| CREATED | 新建未执行 |
| ACTIVE | 正在参与对话 |
| IDLE | 长时间无交互 |
| ARCHIVED | 归档只读 |
| DELETED | 逻辑删除 |
六、多轮对话是如何工作的?
关键逻辑:
def run_chat(conversation_id, user_input):
history = db.load_messages(conversation_id)
history.append(user_input)
response = llm(history)
db.save(response)
return response
本质:
每次请求都重建完整上下文
LLM 不保存状态。
七、在 Agent 模式下的对话管理
在 OpenClaw 中会多一层:
Conversation
└── Task
└── Step
结构示例
{
"conversation_id": "conv_01",
"tasks": [
{
"task_id": "task_001",
"steps": [
{"type":"llm"},
{"type":"tool"},
{"type":"llm"}
]
}
]
}
为什么要这样?
因为:
一个 conversation 里可能有多个复杂任务
例如:
用户先查库存 → 又下订单 → 又审批
八、conversation_id 在 SSE 流式中的角色
SSE 是:
单次 HTTP 连接
但 conversation_id 允许:
HTTP1 -> conv_01
HTTP2 -> conv_01
HTTP3 -> conv_01
实现跨连接连续对话。
九、如何避免上下文爆炸(工程关键)
长对话会导致:
- token 超限
- 推理变慢
- 成本上升
解决方案:
1️⃣ 滑动窗口裁剪
messages = messages[-20:]
2️⃣ 摘要压缩
旧历史 → LLM 生成 summary → 替换历史
数据库保存:
{
"memory_summary": "用户之前讨论了库存问题..."
}
3️⃣ 分段存储 + 向量召回
旧对话写入向量库:
- PostgreSQL
- ClickHouse
- Milvus
需要时召回。
十、多租户隔离(ERP场景必须)
conversation 表必须包含:
tenant_id
org_id
user_id
所有查询必须:
WHERE conversation_id = ?
AND tenant_id = ?
否则:
一个租户可以访问另一个租户对话
这是 SaaS 致命漏洞。
十一、分布式环境下的对话一致性
如果 OpenClaw 多实例部署:
Gateway × N
Worker × M
需要:
1️⃣ 数据库为唯一真源
不要存本地内存状态。
2️⃣ Redis 做分布式锁
防止:
两个 worker 同时执行同一个 conversation。
十二、对话删除策略
推荐:
软删除
{
"deleted": true
}
数据保留周期
例如:
30天自动归档
180天自动清理
符合企业合规。
十三、对话与任务的关系(非常关键)
很多人设计错在这里。
错误:
一个请求 = 一个 conversation
正确:
一个 conversation = 多个任务
一个任务 = 多个步骤
十四、典型执行流程示意
用户:
conversation_id = null
系统:
创建 conv_01
用户第二次:
conversation_id = conv_01
系统:
加载历史
执行 Agent Loop
十五、你如果做 ERP + Agent
建议你设计:
Conversation
├── 类型(chat / workflow / approval)
├── 权限范围
├── 关联业务单据ID
例如:
conv_01 关联 PO#20260305
实现业务可追溯。
十六、总结(本质理解)
conversation_id 是:
LLM 无状态架构下的人造“上下文锚点”
它解决:
- 多轮连续性
- 状态恢复
- 审计记录
- 分布式一致性
- 多租户隔离
它不是:
- 用户登录凭证
- 会话cookie
- 任务ID
